Predicción de cosecha mediante Teledetección y Aprendizaje Automático
31/07/2017
ParajeInnova
Predicción de cosecha mediante Teledetección y Aprendizaje Automático
La importancia de la predicción de la cosecha
La predicción de cosecha es una herramienta que se ha mostrado muy útil a diversas escalas. Por ejemplo, permite a los operadores de mercados de futuros realizar sus operaciones con estimaciones objetivas de rendimientos, lo que les permite afinar más en sus transacciones. También permite a las agencias de ayuda contra el hambre a prever malas cosechas en países susceptibles de hambruna, con lo que se pueden realizar previsiones de envío de ayuda humanitaria. Así mismo, los operadores logísticos de productos agrícolas pueden organizar con antelación las necesidades de transporte en barcos, trenes, camiones, etc. También las empresas agroalimentarias pueden programar compras de unos u otros proveedores y, además, las compañías aseguradoras pueden hacer previsiones en cuanto al volumen global de desembolsos de posibles indemnizaciones. Por último, los gobiernos pueden hacer una mejor política de planificación agraria y ordenación de las políticas de mercado. Y a escala local, puede permitir al agricultor ajustar el uso de fertilizantes, ya que la cosecha esperada suele ser uno de los parámetros a contemplar de forma previa a cualquier recomendación de abonado.
Es una labor complicada
La predicción de cosecha es una labor ciertamente complicada. Modelizar matemáticamente el medio agrícola es un reto que se lleva abordando desde hace décadas. El problema reside en que este es un entorno complejo, afectado por multitud de variables (suelo, meteorología, nutrientes, plagas, manejo, etc.), muchas de ellas, a su vez, de difícil modelización. Por ejemplo, un cultivo puede ir evolucionando de forma óptima, pero sufrir una importante granizada cerca de la cosecha y echar al traste cualquier predicción previa. Está claro que es realmente improbable que un modelo matemático prediga algo así con antelación suficiente. En todo caso, en el campo agrario, como en muchos otros, hay que emplear en muchas ocasiones la máxima de “mejor una aproximación que una conjetura”.
Actualmente hay diversos modelos de predicción de cosecha. Unos son públicos, como Aquacrop, de la FAO (Organización de las Naciones Unidas para la Alimentación y la Agricultura), que es el que utiliza el Instituto Tecnológico Agrario de Castilla y León (ITACyL) para sus estimaciones; o el MARS (Monitoring Agricultural Resources), de la Unión Europea, que es el que usa la Comisión Europea para la gestión de la PAC. Otros son privados, y muchos otros son experimentales. Los modelos más conocidos usan fundamentalmente una aproximación estadística y meteorológica al problema, si bien los hay que integran también, por ejemplo, imágenes de satélite y muestreos a pie de campo.
Una aproximación simple, que no simplista
En la empresa Paraje Innova nos propusimos el desarrollo de un modelo matemático de predicción de cosecha propio, con el fin de utilizarlo en diversas iniciativas que estamos poniendo en marcha. Para ello, nos planteamos la premisa de simplificar en lo posible los datos de partida, y utilizar la mejor tecnología a nuestro alcance para desarrollar dicho modelo.
Dado que la finalidad que se busca en el modelo es la de predecir, antes de finalizar la campaña (y preferiblemente con bastante antelación), la cosecha que se va a obtener, se necesitan varios elementos para lograrlo.
En primer lugar, unas variables en las que basar la predicción de cosecha. En este caso, se optó por utilizar reflectancia espectral del cultivo en varias fechas durante su desarrollo. Esta información espectral, es decir, de la energía reflejada por el cultivo en varias longitudes de onda, se puede captar desde diversas plataformas, pero siempre mediante sensores multiespectrales montados en aeronaves tripuladas, UAVs o RPAS (popularmente conocidos como drones), equipos manuales de campo, equipos embarcados en vehículos terrestres, o satélites.
En segundo lugar, un sistema de modelización. En este caso utilizamos una herramienta de gran actualidad, como es el software de “Aprendizaje Automático”, o “Machine Learning”, en inglés. Este tipo de software utiliza técnicas de inteligencia artificial para aprender a partir de ejemplos (clasificación) u ordenar elementos por similitud (agrupamiento o clustering), y se utiliza en aplicaciones tan dispares como la meteorología, la predicción de valores bursátiles, la recomendación de compras o los sistemas de conducción autónoma, entre muchos otros.
Y en tercer y último lugar, una amplia cantidad de campos con suficiente variabilidad en los que tomar datos, y de los que conociésemos con precisión la cosecha obtenida al final de la campaña, con el fin de poder ofrecer los datos necesarios para que nuestro modelo pudiese “aprender a predecir”. El Centro Tecnológico Agrario y Agroalimentario (ITAGRA.CT) dispone de una extensa red de campos de ensayo, entre los cuales se encuentran varios de trigo blando, tanto de variedades como de fertilización, en los que se encuentran decenas de microparcelas. Gracias a esto, se pueden capturar gran cantidad de datos de gran calidad con un despliegue moderado de recursos.
Desarrollo del modelo
Este primer modelo que se ha desarrollado se ha enfocado al trigo blando, y para elaborarlo se ha partido de los datos recopilados en dos campañas (2015 y 2016) en las microparcelas de cuatro campos de ensayo de trigo blando en secano situados en la provincia de Palencia, gestionados, como se ha indicado anteriormente, por ITAGRA.CT. En total supusieron 436 microparcelas de 10×1,2m, repartidas en dichos cuatro campos de ensayo, uno de variedades y tres de fertilización.
Durante la primera campaña se realizaron 3 vuelos con dron en 3 fechas clave del desarrollo del cultivo, coincidiendo con los meses de abril, mayo y junio. Las imágenes se captaron con un vehículo de ala fija operado por personal de la empresa palentina colaboradora en el proyecto, Überbaum Industrie, S.L. Este dron se equipó con una cámara multiespectral, capaz de capturar imágenes en las tres bandas del espectro visible (rojo, verde y azul), más el rojo extremo y el infrarrojo cercano, con una resolución de 4 cm.
 Personal de Überbaum instalando la cámara en el dron de ala fija.
Debido a la necesidad de poder relacionar los datos tomados en las distintas fechas en distintos vuelos, con distintas condiciones de iluminación y de operación, se realizó una calibración geométrica y radiométrica de las imágenes. La calibración geométrica se efectuó mediante el uso de dianas y un GPS Leica 1200 conectado a la red GNSS del ITACyL, alcanzando errores inferiores a 5 cm en los ejes XYZ. En cuanto a la calibración radiométrica, se realizó mediante el uso de dianas radiométricas y un espectrorradiómetro de campo ASD Fieldspec, con la colaboración de miembros del Grupo de Óptica Atmosférica de la Universidad de Valladolid (GOA-Uva).
Personal de Überbaum instalando la cámara en el dron de ala fija.
Debido a la necesidad de poder relacionar los datos tomados en las distintas fechas en distintos vuelos, con distintas condiciones de iluminación y de operación, se realizó una calibración geométrica y radiométrica de las imágenes. La calibración geométrica se efectuó mediante el uso de dianas y un GPS Leica 1200 conectado a la red GNSS del ITACyL, alcanzando errores inferiores a 5 cm en los ejes XYZ. En cuanto a la calibración radiométrica, se realizó mediante el uso de dianas radiométricas y un espectrorradiómetro de campo ASD Fieldspec, con la colaboración de miembros del Grupo de Óptica Atmosférica de la Universidad de Valladolid (GOA-Uva).
 En primer plano, Luis Carlos Fernández, de Paraje Innova, tomando puntos de apoyo con un GPS para la calibración geométrica de las imágenes. Imagen de fondo, ortofoto en visible de uno de los campos. Se observan en la parte superior izquierda las dianas radiométricas (de colores), y en el centro y derecha, las utilizadas para corrección geométrica (con cruces).
En primer plano, Luis Carlos Fernández, de Paraje Innova, tomando puntos de apoyo con un GPS para la calibración geométrica de las imágenes. Imagen de fondo, ortofoto en visible de uno de los campos. Se observan en la parte superior izquierda las dianas radiométricas (de colores), y en el centro y derecha, las utilizadas para corrección geométrica (con cruces).
 Ramiro González Catón y Cristian Velasco Merino, del GOA-Uva, midiendo con espectroradiómetro reflectancias en paneles de colores para la calibración radiométrica de las imágenes. A la derecha de la fotografía se ve parcialmente un panel de los utilizados para la calibración geométrica.
Se trataron las imágenes obtenidas en los vuelos utilizando un software de procesado fotogramétrico, gracias al cual se generaron los mosaicos u ortofotos de cada campo en cada fecha y para cada banda indicada anteriormente. A partir de dichos mosaicos se calcularon mediante software de Sistemas de Información Geográfica (SIG), diversos índices de vegetación. Estos índices son combinaciones, relaciones matemáticas, derivadas de las propiedades de reflectancia de la vegetación y su entorno, en dos o más longitudes de onda, y están diseñados para realzar una o varias propiedades de la vegetación. El más “popular” es el NDVI, que representa la relación entre la resta del valor del infrarrojo cercano menos el valor del canal rojo y la suma de las mismas longitudes de onda. Este índice está directamente relacionado con la actividad fotosintética. Para este proyecto se calcularon, además del NDVI, otros índices como EVI, GNDVI y SAVI, entre otros.
Ramiro González Catón y Cristian Velasco Merino, del GOA-Uva, midiendo con espectroradiómetro reflectancias en paneles de colores para la calibración radiométrica de las imágenes. A la derecha de la fotografía se ve parcialmente un panel de los utilizados para la calibración geométrica.
Se trataron las imágenes obtenidas en los vuelos utilizando un software de procesado fotogramétrico, gracias al cual se generaron los mosaicos u ortofotos de cada campo en cada fecha y para cada banda indicada anteriormente. A partir de dichos mosaicos se calcularon mediante software de Sistemas de Información Geográfica (SIG), diversos índices de vegetación. Estos índices son combinaciones, relaciones matemáticas, derivadas de las propiedades de reflectancia de la vegetación y su entorno, en dos o más longitudes de onda, y están diseñados para realzar una o varias propiedades de la vegetación. El más “popular” es el NDVI, que representa la relación entre la resta del valor del infrarrojo cercano menos el valor del canal rojo y la suma de las mismas longitudes de onda. Este índice está directamente relacionado con la actividad fotosintética. Para este proyecto se calcularon, además del NDVI, otros índices como EVI, GNDVI y SAVI, entre otros.
Al final de la campaña, ITAGRA.CT proporcionó, entre otros parámetros, los resultados del rendimiento en grano obtenido por cada microparcela en cada uno de los campos, en kg/ha al 13-14% de humedad.
Todos los datos recopilados esta campaña se introdujeron en el software de aprendizaje para el desarrollo del modelo. La generación de este modelo no es totalmente automática. Existen gran cantidad de algoritmos disponibles que funcionan mejor o peor según el tipo y características de los datos de entrada, y a su vez estos admiten también gran cantidad de parámetros. Por otro lado, los datos de entrada también son susceptibles de ser preprocesados y filtrados. Así pues, el proceso de aprendizaje automático es relativamente complejo.
Resultados obtenidos en la primera campaña
Tras diversas pruebas con distintas combinaciones de bandas espectrales e índices de vegetación, se pudo comprobar que el índice NDVI es el que mejor funciona para esta aplicación.
Para comprobar la validez del modelo se hicieron tres rondas de pruebas. Dos utilizando los índices NDVI de las tres fechas (abril, mayo y junio), y una utilizando solo las de las dos primeras fechas (abril y mayo). En cada una de ellas se generó el modelo, utilizando validación cruzada (cross-validation, en inglés), y sin contar con los datos de 6 ó 7 microparcelas “test”, en cada caso distintas, y tomadas al azar de dos de los campos, y se indicó a cada modelo que predijese los rendimientos para esas microparcelas “desconocidas”. Los resultados se muestran en los Gráficos 1 al 3.
 Resultados del primer test, utilizando los índices NDVI de tres fechas y con datos de 6 microparcelas de test. La fecha de la predicción es el 2 de junio. Correlación 94,20%. Error absoluto medio 404,64. Todos los valores en kg/ha.
Resultados del primer test, utilizando los índices NDVI de tres fechas y con datos de 6 microparcelas de test. La fecha de la predicción es el 2 de junio. Correlación 94,20%. Error absoluto medio 404,64. Todos los valores en kg/ha.
 Resultados del segundo test, utilizando los índices NDVI en tres fechas y con datos de 7 microparcelas de test. La fecha de la predicción es el 2 de junio. Correlación 97,53%. Error absoluto medio 183,88. Todos los valores en kg/ha.
Resultados del segundo test, utilizando los índices NDVI en tres fechas y con datos de 7 microparcelas de test. La fecha de la predicción es el 2 de junio. Correlación 97,53%. Error absoluto medio 183,88. Todos los valores en kg/ha.
 Resultados del tercer test, utilizando los índices NDVI de dos fechas y con datos de 7 microparcelas de test. La fecha de la predicción es el 6 de mayo. Correlación 99,00%. Error absoluto medio 218,98. Todos los valores en kg/ha.
Resultados del tercer test, utilizando los índices NDVI de dos fechas y con datos de 7 microparcelas de test. La fecha de la predicción es el 6 de mayo. Correlación 99,00%. Error absoluto medio 218,98. Todos los valores en kg/ha.
Metodología de la segunda campaña
En la campaña 2015-2016 se simplificó el sistema de captura de datos. Visto que el mejor índice para desarrollar el modelo era el NDVI, se optó por hacer directamente las mediciones de éste microparcela por microparcela, en los 2 campos de ensayo seleccionados para esa campaña. Para ello se contó con un equipo muy conocido en el sector, un GreenSeeker de Trimble cedido por ITAGRA.CT. Este equipo emite ráfagas de luz roja e infrarroja hacia el cultivo, y detecta la porción de luz de cada tipo que es reflejada. A partir de esos datos ofrece el índice NDVI. Dado que el equipo emite su propia luz, no es necesario someterlo a calibraciones según las condiciones lumínicas existentes, por lo que las mediciones hechas con este aparato son siempre comparables entre sí.
 Alberto Sanz, de Paraje Innova, realizando mediciones del NDVI mediante el GreenSeeker.
En este caso se hicieron mediciones en abril y junio en uno de los campos, y en abril, mayo y junio en el otro, midiendo el NDVI de cada microparcela. Al igual que en la campaña anterior, desde ITAGRA.CT se proporcionaron los datos de rendimiento en grano obtenido en cada microparcela. Con toda esta información, se procedió a hacer nuevas pruebas en el software de aprendizaje automático.
Alberto Sanz, de Paraje Innova, realizando mediciones del NDVI mediante el GreenSeeker.
En este caso se hicieron mediciones en abril y junio en uno de los campos, y en abril, mayo y junio en el otro, midiendo el NDVI de cada microparcela. Al igual que en la campaña anterior, desde ITAGRA.CT se proporcionaron los datos de rendimiento en grano obtenido en cada microparcela. Con toda esta información, se procedió a hacer nuevas pruebas en el software de aprendizaje automático.
Resultados obtenidos de la segunda campaña
En primer lugar se comprobó la robustez del modelo obtenido en 2015. Para ello se probó dicho modelo con los valores de NDVI obtenidos en 2016 en un campo de testeo. Como resultado se obtuvo una predicción con un error absoluto medio de aproximadamente 329 kg/ha y un ajuste entre predicción y realidad del 56,9%. Es decir, la predicción de cosecha empeora sensiblemente entre campañas, como era de esperar.
En segundo lugar se unificaron los datos de todos los campos y de ambas campañas. Con esta base de datos ampliada se generaron varios modelos de predicción de cosecha que se mejoraron también mediante validación cruzada.
En este punto conviene indicar que existen dos principales problemas de cara a predecir el rendimiento de un campo a partir de varios valores NDVI. El primero, es que los valores de este índice son siempre relativos, salvo que se calibren las fuentes de adquisición o las imágenes adquiridas para cada condición lumínica. El segundo, es que no siempre podemos tomar los datos en las mismas fechas o en el mismo estado fenológico exacto del cultivo, de un año para otro.
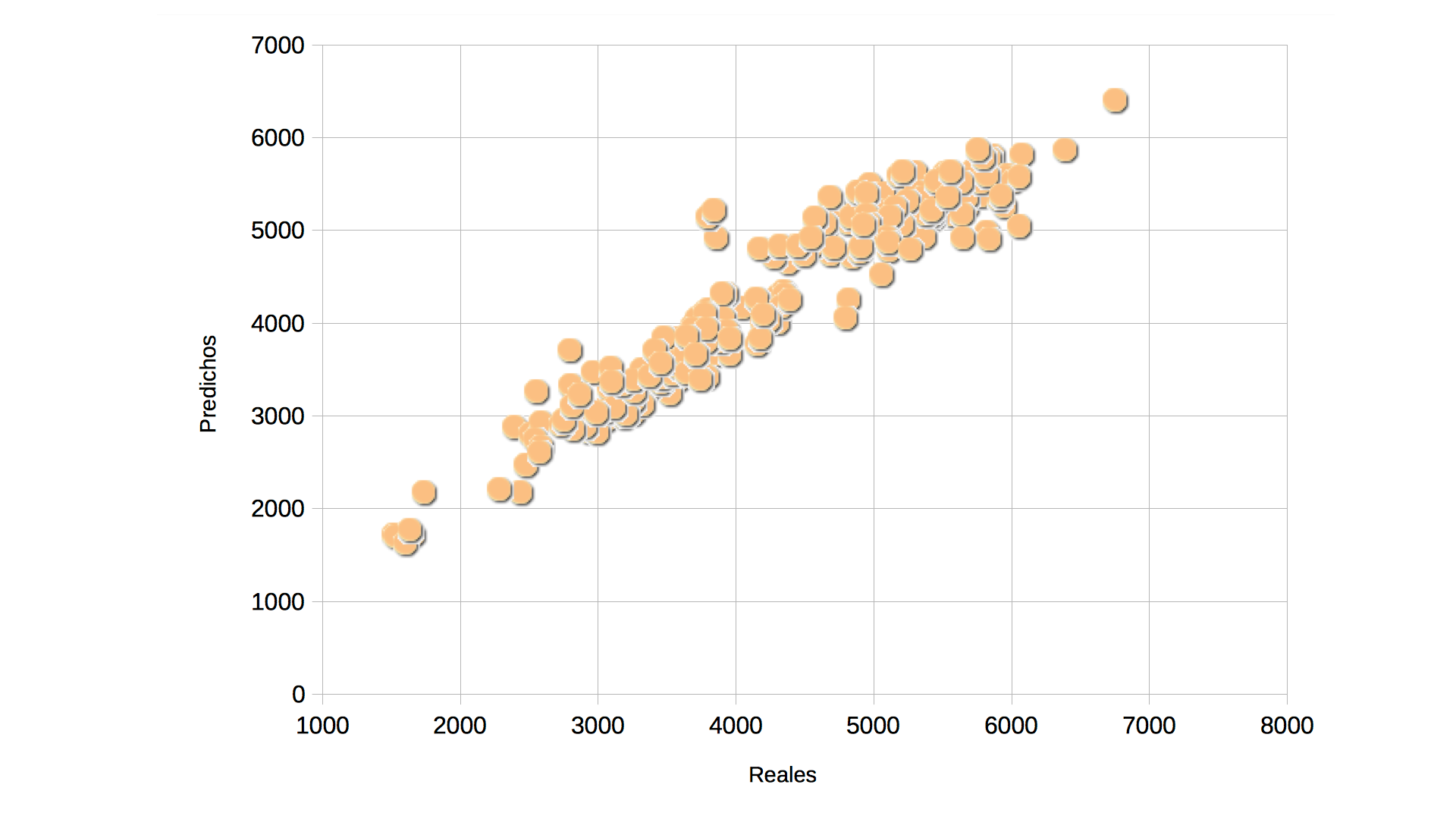
En este proyecto, el primer problema se solventó como se indicó anteriormente, mediante el uso de datos calibrados, y el segundo, mediante la consideración en los datos de partida que alimentan el modelo de una referencia temporal de la medición del índice NDVI en cada campo. Aplicando este sistema se ha obtenido un nuevo modelo resultante de ambas campañas con un ajuste de un 95,5% y un error medio absoluto de 254 kg/ha.
Predicciones de rendimiento realizadas en los cuatro campos de ensayo durante las campañas de 2015 y 2016. En el eje horizontal, los pesos reales obtenidos en cada microparcela. En el eje vertical, los predichos por el modelo.
Próximos pasos
Viendo el comportamiento del modelo, puede deducirse que el uso del índice NDVI durante la campaña es una buena herramienta para predecir el rendimiento en cosecha que se va a obtener del trigo blando en secano. Como se ha indicado con anterioridad, el estudio ha sido desarrollado en un entorno limitado, tanto en tiempo (dos campañas) como en espacio (4 campos de ensayo en la provincia de Palencia). Es nuestro deseo ampliar la zona y periodo de estudio, así como disminuir la escala de trabajo, utilizando también imágenes de satélite, para poder utilizar el modelo en grandes extensiones.
Por otra parte, creemos de gran interés el desarrollo de modelos de predicción de cosecha para otros cultivos herbáceos, como la cebada, el centeno, la avena o el maíz, o leñosos, como el viñedo. En este último caso para al algo tan necesario como prever aforos y poder organizar la vendimia.
Hasta aquí, el importante esfuerzo en horas y equipos tanto de Paraje Innova como de las entidades citadas y de sus técnicos, que ha dado como resultado un modelo de predicción de cosecha que promete ser válido para el fin previsto. El modelo necesita continuar su desarrollo para conseguir alcanzar una más perfecta calibración, exactitud y precisión, además de poderse aplicar a otros cultivos. Para esta siguiente fase los promotores esperan el apoyo de organizaciones o entidades que puedan sentirse interesadas en este desarrollo.
A todos los técnicos y entidades que han colaborado en este proyecto, nuestro más profundo agradecimiento por su apoyo y estímulo.